

This morning I was reading two papers, both making somewhat bold claims. One mentioned that despite the lack of relationships between the menstrual cycle phase and perceived recovery, objective sleep quality was impacted. Another one claimed heart rate could be used to assess kidney function.
In an age where data is abundant, wearables and connected devices are constantly calculating, estimating, and interpreting. Often, wearables offer metrics derived not from direct measurements but from other data points that correlate—loosely or tightly—with the variables we care about (variables that we are not able to measure as ‘conveniently’).
There are two different issues here: one is the reliance on inaccurate output as a reference for our findings (e.g. the sleep study) while the other one is using loosely correlated parameters over a large population to infer unproven practical implications at the individual level (this reminds me a lot of ‘low HRV and mortality’).
In the menstrual cycle and sleep study, a contactless device (Somnofy sleep monitor) was used. To determine sleep stages, something that should be done by monitoring brain waves, muscle activity, and eye movement, a device that cannot measure any of these things is used instead. Then, conclusions are derived, claiming that ‘objective sleep quality’ is dependent on the menstrual cycle phase, despite no change in perceived recovery (please, authors, take no offense, this is just one of many studies doing this, and I am using it as an example of a problematic trend).
In the heart rate and kidney function study, we have such a wide range of resting heart rates (50 to 102 beats per minute) - because of the large dataset - that literally any health or performance outcome would correlate with it. However, there are no practical implications for the individual, as the range of heart rate values for people e.g. with / without kidney issues, is basically the same (54 to 99 beats per minute vs 52 to 102 beats per minute).
Let’s dig deeper into why relying on these indirect metrics and correlation-based estimates can create issues, especially when we're dealing with individual health and performance.
Estimates vs. Measurements
This is a topic I covered in more detail here, but I will report below the most important points.
To measure something, we need a sensor that can do the job, according to what is an established method to measure such parameter. For example, a wearable can include an optical sensor that can measure changes in blood flow as the heart beats via PPG (photoplethysmography), and therefore - under certain circumstances - we can consider this a direct measurement of your pulse rate (and its variability, or PRV).
On the other hand, when we estimate something, we take a guess. We can take this guess in different ways, from simple (e.g. determining your maximal heart rate based on your age) to more complex (e.g. determining your sleep stages using a machine learning model whose inputs are a number of heart rate variability, movement, temperature, and circadian features). In both cases, this is just a guess. To actually measure your maximal heart rate you would need to do a maximal test (or similar). To actually measure your sleep stages you would need to measure brain waves, eye movement, and muscle activity - none of these things are measured by a wearable when providing sleep stages.
The distinction between measurements and estimates is mostly a practical one (as in fact, we could say we are always estimating to a certain degree), but I think this distinction can be a useful tool to draw a line between things that our device can capture because of a direct measurement via the sensors that are included in the device, and things that our device is trying to guess because they might be somewhat related to the other parameters that the included sensors can measure. The likelihood of getting it wrong at the individual level is much higher when we rely on less direct measurements (e.g. sleep stages or blood pressure from PPG), or incorrect assumptions (e.g. continuous HRV as stress estimate), with respect to more direct measurements (e.g. pulse rate).
Since I’m all for keeping things practical and not just theoretical, here is a useful heuristic to navigate the world of estimates:
When in doubt, compare or look for comparisons of multiple devices. If the output of multiple wearables for a given parameter is inconsistent over time, for the same individual, then it is a clear red flag that we are unable to estimate the parameter with the required accuracy.
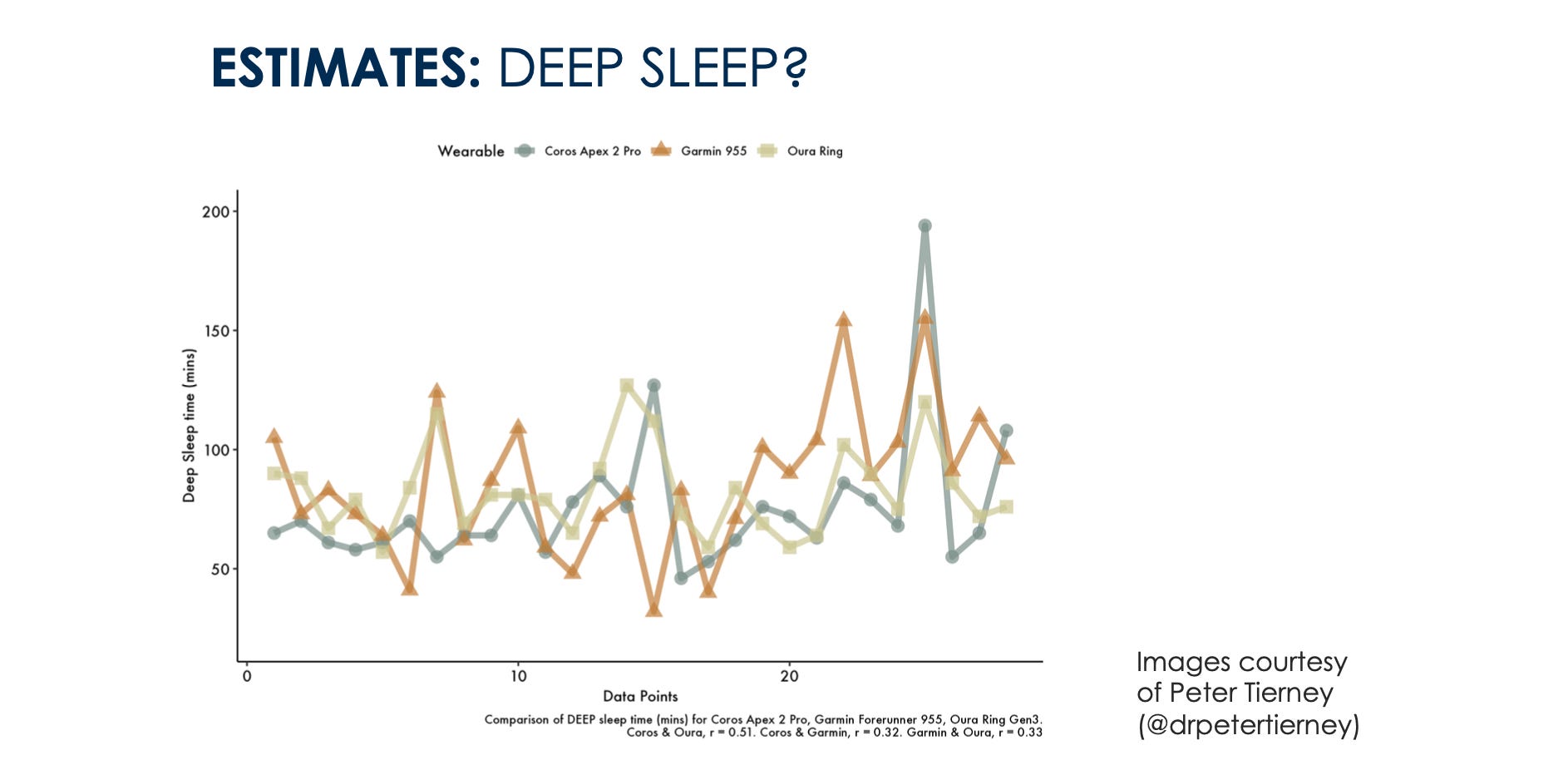
Take sleep stages, one of the most popular features in today’s wearables. The problem? Different devices use different algorithms to predict sleep stages, each relying on proxies like heart rate variability, movement, skin temperature, etc. These variables only approximate sleep stages and may differ significantly from each other and from polysomnography, the gold standard. Put two sleep wearables side-by-side, and you’ll likely get two different sleep stage interpretations. And if you’re tracking these stages to improve sleep, which one do you trust?
How can we conclude that the mid-luteal phase had more light sleep if we tracked sleep stages with a sensor placed on a nightstand? I do not think we can make these claims unless we are tracking sleep stages with polysomnography, unfortunately.
If our conclusions and future interventions change just because we bought a sensor instead of another one, then we have a problem.
This level of nonsense is fine for Reddit, but it bothers me when I see it in a scientific paper. We need to have higher standards. If we cannot fit a proper sleep assessment in our study, then it is fine, and we should just use subjective sleep quality.
Group-Level Precision, Individual-Level Ambiguity
The issue that arises from the second study (heart rate and kidney function) is different, but also very common.
When we look at large datasets, using correlated metrics can appear remarkably accurate. We see this trend everywhere, with VO2max, blood pressure, and even mental health states being ‘estimated’ by devices based on loosely correlated data points. However, just because two variables share a correlation (under certain circumstances) it doesn’t mean we can reliably derive one from the other at the individual level.
For example, in the context of performance, we know that VO2max is a good predictor - given a large enough sample of individuals with a wide range of VO2max values. However, in a homogenous sample, VO2max is a poor predictor of performance: if you take a group of elite runners, and rank them by their VO2max, this ranking won’t match their actual running times - there is more to running performance than VO2max. As an individual, I cannot use my VO2max to predict my performance (and here I mean my actual VO2max, not even an estimate of it).
Another example is blood pressure, which can be estimated from PPG data, heart rate, and HRV, even though none of these metrics is an actual measure of arterial pressure. The implications of relying on correlation-based estimates are serious when considering diagnostic purposes. Imagine being told your blood pressure is elevated based on PPG data alone. Without a more direct measurement, you could receive misleading information, especially if your body doesn’t fit the population-level norms on which the estimate is based. Maybe your PPG has a slightly different waveform from the original dataset used to develop the algorithm, and as such, your blood pressure estimate is quite far off.
This is the direction we are heading to as literally everything is correlated if you measure it on a wide enough range of individuals or a wide enough range of activities. It is somewhat interesting how wearables claim to be bringing you personalization and individualization but mostly rely on population-level estimates that have not proven to capture individual data accurately - or most importantly - to track within-individual changes over time accurately - even though that’s how they are used by consumers.
Of the wealth of metrics available at our fingertips, much of it is only loosely reflective of our true physiological state. When these estimates form the basis of health recommendations, we risk creating interventions that are built on guesswork rather than precise insight.
Wrap up
Wearables and their manufacturers may continue to push the narrative that everything is interconnected and therefore measurable. Well, to a certain extent, that is true.
But the critical question is whether we can truly trust these estimates at the individual level, and not only for population averages.
Unfortunately, I do not think that is the case due to the gaps between more direct measurements and estimates, as well as between population-level validations and our ability to assess within-individual longitudinal changes. Issues and limitations that need to be acknowledged, if we want to make effective use of these devices.
For the foreseeable future, I will keep relying on actual measurements of my resting physiology and its variation over time, with respect to my normal range, as a valid assessment of how my body is responding to the various stressors present in my life.

Marco holds a PhD cum laude in applied machine learning, a M.Sc. cum laude in computer science engineering, and a M.Sc. cum laude in human movement sciences and high-performance coaching.
He has published more than 50 papers and patents at the intersection between physiology, health, technology, and human performance.
He is co-founder of HRV4Training, advisor at Oura, guest lecturer at VU Amsterdam, and editor for IEEE Pervasive Computing Magazine. He loves running.
Social:

Very educational. Thank you very much!
Ciao Marco
Very interesting post, I have been following you for a while now, I love your "no BS" approach.
I wanted to ask you, if wearable metrics are derived from population-level estimates, which often miss the mark on individual accuracy, does this make the search for clinical biomarkers based on wearable data less meaningful? Because I see a lot of current research on this relying on cross-sectional data.
In your opinion, do we need more longitudinal studies that focus on validating within-individual changes over time? Is this a necessary step before wearable-based biomarkers can genuinely support clinical outcomes?
I hope I'm not asking too much :) look forward to hearing your thoughts, thanks a lot!
Marcello